Les techniques de transmission de l'information.Dans ce chapitre, nous allons ťtudier toujours de le cadre de la transmission des donnťes, comment on prťpare ces donnťes en vue díune transmission oý l'on peut gr‚ce ŗ un codage appropriť amťliorer la qualitť, la vitesse ou la quantitť des donnťes transmises.
Le codage des informations.
Le codage des informations est utilisť dans les transmissions, aussi bien en bande de base qu'en bande dťcalťe, pour ťviter la transmission d'erreurs.
Une erreur ťtant toujours inacceptable, il convient pour líťviter, de fournir, en plus des donnťes, un code qui permet, dans le pire des cas, de dťtecter les erreurs et dans le meilleur, de les corriger.
Le codage de la paritť.
Le code le plus simple pour transfťrer une information est le codage de la paritť. Cette mťthode, la plus ťlťmentaire, fut l'une des premiŤres ŗ Ítre utilisťe.
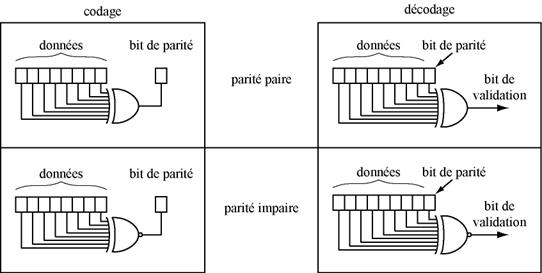
Son principe est assez simple, il s'agit d'ajouter un bit supplťmentaire aux donnťes transmises. Dans le cas d'une paritť paire, ce bit permet au message d'Ítre composť d'un nombre toujours pair de bits ŗ '1', et dans le cas d'une paritť impaire, un nombre toujours impaire de bits ŗ '1'. Ce codage est rťalisť au moyen de la fonction OU EXCLUSIF pour la paritť paire et NON OU EXCLUSIF pour la paritť impaire.
Au dťcodage, on va utiliser la mÍme fonction logique que celle utilisťe pour le codage pour valider le message. Par exemple avec la paritť paire, on va rťaliser une fonction OU EXCLUSIF entre les n bits du message et le bit de paritť. Si le rťsultat vaut '0', le message est rťputť vrai, si le rťsultat vaut '1' il est rťputť faux.
Il faut toutefois relativiser ce rťsultat, en effet un code de paritť ne sait dťtecter qu'un nombre impair d'erreur. Il lui est impossible de dťtecter deux erreurs. On considŤre donc que les codes de paritť simple ne savent dťtecter qu'une seule erreur.
On peut aussi s'intťresser ŗ la quantitť de bits de contrŰle transmis par message. Dans le cas d'un code de paritť simple, on considŤre en gťnťral qu'il est dangereux de dťpasser une proportion de 1/8 soit un bit de contrŰle pour huit bits de donnťes.
Une ťvolution des codes de paritť consiste ŗ introduire une redondance des codages.
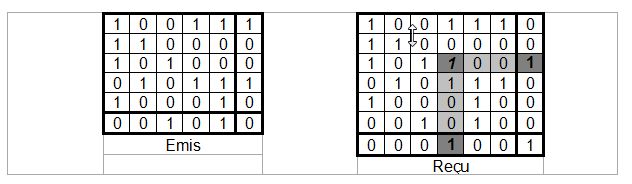
Ainsi, on peut envisager, toujours en utilisant un contrŰle de paritť, de retrouver le bit erronť. Envisageons d'envoyer un message de 5 mots de 5 bits, on peut alors coder de la faÁon suivante le message.
Cotť ťmission, ŗ l'extrťmitť de chaque ligne, on place un bit de paritť paire et on fait la mÍme chose avec les colonnes.
On nomme paritť transverse les bits de paritťs crťťs pour chaque colonne et paritť longitudinale ceux crťťs pour chaque ligne.
Les signaux ťmis sont : 100111 110000 101000 010111 100010 001010 Les signaux reÁus sont : 100111 110000 101100 010111 100010 001010
A la rťception, on rťcupŤre le message qui a ťtť transmis et on lui applique encore une fois un contrŰle de paritť longitudinal et transverse. Si une erreur s'est glissťe dans le code, immanquablement une paritť longitudinale et une paritť transverse sont ŗ '1'. Cela signifie qu'il y a eut une erreur dans la transmission.
Dans notre exemple, en vťrifiant les valeurs de contrŰle, on constate qu'il y a 2 codes de contrŰle non valable, l'un sur une ligne, l'autre sur une colonne. Donc on connaÓt rigoureusement l'emplacement de l'erreur.
Ce code permet donc de corriger líerreur puisquíelle est placťe ŗ líintersection des 2 lignes et colonnes fautives. Toutefois, si ŗ la rťception, il y a deux ou trois erreurs, il y aura toujours systťmatiquement au moins un bit de paritť transverse ou longitudinale ŗ '1'. On peut donc dťtecter jusqu'ŗ trois erreurs. Par contre, on ne peut corriger qu'une seule erreur.
La proportion des bits de contrŰle par rapport aux bits de donnťes, au moment de la transmission, passe (dans notre exemple) de 1/5 (0,2) pour une paritť simple ŗ 11/25 (0,44) pour les paritťs composťes. Les codages redondants.
Les codages redondants augmentent le nombre de bits du message pour permettre de dťtecter d'ťventuelles erreurs et ťventuellement de les corriger.
Le code le plus connu est celui de HAMMING, bien que pratiquement abandonnť, il fut le codes des premiŤres transmissions numťriques.
Exemple.
Imaginons que l'on cherche ŗ transmettre un mot de 4 bits. Le code de HAMMING nous dit que pour n bits d'information, il faut k bits de contrŰle pour corriger une erreur. On peut exprimer k en fonction de n gr‚ce ŗ la formule suivante :
Par itťration, on peut rťsoudre cette ťquation. Pour n = 4, on a k = 3. Cela veut dire que l'on va transmettre 7 bits (m = k + n). Il faut maintenant coder les k bits en vue de la transmission.
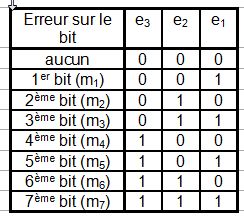
Pour cela on va coder dans un tableau toutes les possibilitťs d'erreur dans le message. Il y a pour un message de m bits, m+1 possibilitť d'erreur. Ce tableau est composť de k (=3) colonnes. D'oý la formule prťcťdente (m+1 = n+k+1 et 2k reprťsente le nombre de ligne identifiable avec k colonnes).
On sort maintenant les ťquations de e1, e2 et e3, et on trouve :
e1=m1 Ň m3 Ň m5 Ň m7 e2=m2 Ň m3 Ň m6 Ň m7 e3=m4 Ň m5 Ň m6 Ň m7 Le signe Ň signifie une addition modulo 2 ce qui peut se traduire par 1Ň1=0. Ň est líopťrateur Ou Exclusif Si líon regarde bien, on se rend compte que les termes m1, m2 et m4 níapparaissent quíune seule fois dans les ťquations. On peut donc en faire (pour simplifier les ťquations) les trois bits de codage de Hamming.
Le message transmis ťtant alors composť de la faÁon suivante :
Pour terminer la rťalisation de notre codage, il reste ŗ remplir le tableau, cíest ŗ dire trouver les valeurs de k1, k2 et k3 qui rendent e1, e2 et e3 nuls. En effet, le message níťtant pas encore ťmis, il níest pas sensť contenir díerreur.
Ce qui donne le tableau suivant :
A la rťception, il suffit de calculer les valeurs de e1, e2 et e3 pour dťfinir síil y a eut une erreur et oý elle se situe. On est alors capable de transmettre un message en dťtectant les erreurs et en les corrigeant.
Ainsi, si le message ŗ envoyer est 1100, on a k3=0, k2=0 et k1=1 donc le message transmis est 1100001. Mais si en route, une erreur apparaÓt sur le 3Ťme bit, le message reÁu devient 1100101, en utilisant le dťcodeur de Hamming, on trouve :
On sait donc oý líerreur se situe car e1, e2 et e3 indiquent une erreur sur le 3Ťme bit. On peut donc corriger le code reÁu et ťcrire que le code sans erreur est 1100001 donc que le message est 1100.
Avec ce code de Hamming, on sait donc corriger une erreur sur un bit mais on est capable, sans les corriger, de dťtecter jusqu'ŗ trois erreurs.
Quand ŗ la proportion des bits de contrŰle, on constate que plus n est grand, plus k augmente, mais pas de faÁon linťaire. Par exemple, si pour dťtecter 3 erreurs, il y a besoin de 3 bits de contrŰle pour 4 bits de donnťes, avec 112 bits de donnťes, il suffit d'utiliser 7 bits de contrŰle.
Attention, rappelons que la probabilitť d'erreur s'accroÓt linťairement avec le nombre de bits transmis. Pour une transmission de 119 bits, le risque d'erreur est donc 17 fois plus grand que pour une transmission de 7 bits. Aussi, pour une telle quantitť de donnťes, il serait raisonnable d'utiliser un code de Hamming plus puissant, c'est ŗ dire capable de dťtecter plus d'erreur. Les codes CRC.
Les codes CRC ou CYCLICAL REDUNDANCY CHECK (contrŰle par redondance cyclique) sont basťs sur une sťrie d'opťrations arithmťtiques.
Tout commence par l'ťlaboration de
la forme polynomiale du message binaire. Par exemple, 110100, c'est ŗ dire
s'ťcrit sous forme polynomiale x5+x4+x2. On nomme ce polynŰme P(x). Puis on applique la formule suivante :
Oý G(x) est un polynŰme, dťfini par le protocole du Rťseau, connu de l'ťmetteur et du rťcepteur et de degrť v. Q(x) est le quotient de la division de P(x).xv par G(x) et donc R(x) est le reste de la division. Puisque G(x) est de degrť v, R(x) est forcťment d'un degrť infťrieur ou ťgal ŗ v. C'est ce reste R(x) qui va Ítre transmis en plus de P(x) au rťcepteur.
A l'arrivťe, on connaÓt donc R(x) (le reste transmis avec le message), v (qui est obtenu par analyse de G(x)), G(x) (connu par dťfinition) et P(x) (le message transmis). On va alors refaire le mÍme calcul que celui rťalisť par l'ťmetteur et comparer les restes des deux divisions.
Síil y a une diffťrence entre les deux restes, on est sŻr alors qu'une erreur s'est glissťe dans la transmission.
G(x) est dťfini par la norme de transmission utilisťe. L'avis V41 de la norme CCITT (Comitť Consultatif International pour le Tťlťgraphe et le Tťlťphone) dťfinit G(x) comme : G(x)=x16+x12+x5+1
Pour le Rťseau CAN, le code G(x) vaut x15+x14+x10+x8+x7+x4+x3+1
Et c'est lŗ que l'on constate l'efficacitť du code CRC, puisque dans le cas du bus CAN, il permet de repťrer les erreurs suivantes :
∑ Toutes les salves d'erreurs comportant un nombre impair de termes ∑ Toutes les salves d'erreurs comportant moins de 17 bits. ∑ 99,998% des salves d'erreurs de plus de 16 bits.
C'est ce qui fait que le codage CRC est trŤs utilisť pour les supports peu fiables, mais aussi dans la majeure partie des Rťseaux.
Du point de vue des proportions entre le nombre de bits de donnťes et le nombre de bits de contrŰle, on constate que, par exemple, le Rťseau Ethernet utilise un code CRC de 32 bits qui lui permet d'assurer la sťcuritť de sa trame de donnťe qui peut contenir jusqu'ŗ 1526 octets, soit un rapport de 4/1526 (0,0026).
Plus gťnťralement, les codes CRC sur 64 bits sont utilisťs par les logiciels de compression de donnťes (ZIP ou RAR) pour valider des fichiers pouvant atteindre plusieurs dizaine de Mťga octets.
Correction d'erreurs de transmission.
Dans le monde des Rťseaux, les codes ne sont lŗ que pour dťtecter les erreurs de transmission, mÍme si ils sont capables de les corriger. La capacitť de transfert des Rťseaux moderne, et la sensibilitť des donnťes, sont telles que l'on prťfŤre retransmettre un paquet si il est susceptible de contenir des erreurs plutŰt que d'en commettre de nouvelles par des corrections hasardeuses.
|