TCP et UDP
e protocole IP permet, comme on l'a vu dans le chapitre précédent, de transférer une information vers une machine cible, de façon non connecté, c'est ŕ dire en ne s'occupant ni de la façon dont les données sont transmise, ni de l'ordre dans lequel elles arrivent, ni męme en se posant la question de la capacité de la machine cible ŕ les recevoir. Il manque donc un élément trčs important dans le dialogue sur les Réseaux, le contrôle du flux. C'est le rôle de la couche de transport autrement dit de TCP ou de UDP. Avant de détailler ces deux protocoles, il existe une notion importante liée aux protocoles de transport, c'est la notion de port. Un port est un point d'accčs ŕ un ou plusieurs services (c'est ŕ dire un ou plusieurs protocoles internes ŕ la machine), ces services correspondent ŕ une tâche (ou un processus) prise en charge par la machine. Comme ces processus sont susceptibles d'ętre créés ou détruit, qu'ils n'ont pas forcément toujours le męme numéro de tâche, il faut passer par un numéro arbitraire, c'est le numéro du port. Les numéros de port sont codés sur 16 bits (de 0 ŕ 65 535) et ils sont classés selon 3 catégories. · Les numéros de 0 ŕ 1023 sont appelés les "Well Known Port", ils correspondent ŕ des applications systčme fondamentales dűment enregistrées et reconnues de tous, ouverte et publiées sous forme de RFC. Elles sont gérées par le IANA (Internet Assigned Number Autority). · Les numéros de port supérieurs ŕ 1023 sont appelés les "Registered Port", ils peuvent ętre utilisé en fonction des disponibilités comme ephemeral ports (les ports utilisés pour lancer des requętes) ou sont propriétés de logiciels privés. Pour toute machine il existe 2 modes de fonctionnement. Le mode serveur et le mode client. Une machine serveur ne propose pas ses services, elle attend qu'un client les lui réclame. Le client est donc le demandeur, et c'est donc toujours le client qui initie une transaction avec un serveur. Le client utilise donc un de ses ports (un ephemeral port) non utilisé par une de ses application pour initier le dialogue avec un Well Known Port du serveur. Prenons l'exemple d'une communication HTTP entre un client et un serveur, le client utilisera un port quelconque (X) pour parler au port 80 du serveur. Celui ci lui répondra depuis le port 80 vers le port X du client. La double paire composée de l'adresse IP et du numéro de port, coté serveur et coté client, est communément nommée Socket. Une Socket doit toujours ętre unique c'est ŕ dire qu'il ne doit jamais il y avoir deux socket utilisant en męme temps un męme port source de la machine source et un męme port de destination de la machine de destination. UDP.Le protocole UDP (User Datagram Protocol) est une version simplifiée du protocole de transport TCP. Il n'assure pas les fonctions de mode connecté, c'est ŕ dire qu'il ne contrôle pas la fiabilité des échanges, et il ne gčre pas le flux. Il est utilisé comme une pseudo interface logicielle au protocole IP lui permettant de fonctionner avec des ports donc de créer des socket.
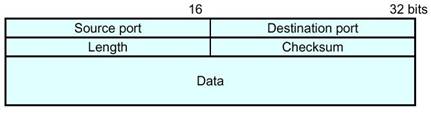
· Le champ Source Port donne le numéro du port de la machine source. il est optionnel. Dans ce dernier cas, il est mis ŕ zéro. · Le champ Destination Port donne le numéro du port de la machine cible. · Le champ Length donne la taille totale, en octets, du paquet UDP, donnée comprise. Il ne doit pas ętre inférieur ŕ 8. · Le champ Checksum est un CRC sur l'entęte UDP ainsi que le pseudo entęte (étudié juste aprčs) et qui n'est pas transmis. Le pseudo entęte UDP n'est pas transmis, mais il est utilisé pour calculer le checksum. Il est composé de 5 champs.
· Le champ Zero est composé de 8 bits ŕ 0. · Le champ Proto contient la copie du champ Protocol de l'entęte IP. Il vaut donc, dans le cas de trame UDP, toujours, la valeur 17. · Le champ UDP Length est la copie du champ Length de l'entęte UDP (c'est ŕ dire qu'il ne tiens pas compte de la taille du pseudo entęte). En contrepartie de sa faible sécurité, UDP présente quelques avantages : sa rapidité (peu de contrôles ŕ réaliser) et son efficacité (le rendement de transmission de UDP est excellent). Son domaine d'utilisation se réduit donc ŕ des applications nécessitant rapidité et simplicité. TCPLe protocole TCP est un protocole de transmission permettant un fonctionnement en mode connecté, contrairement au protocole IP qui est un protocole sans connexion. Le mode connecté signifie qu'il y a une vraie relation entre l'émetteur et le récepteur. Cela sous entend que les deux machines vont s'accorder sur leur capacité ŕ gérer les échanges, ŕ gérer les congestion du Réseau, les pertes de données, les erreurs… En mode connecté, les échanges ne sont donc plus exclusivement des échanges de données, il y a aussi des trames qui circulent en vue de la synchronisation des échanges de données. Ainsi lorsque une machine émet un message Mi, elle s'attend ŕ recevoir un acquittement Ai, si celui ci arrive, elle envoie alors le message suivant Mi+1. Si il n'y a pas d'acquittement de reçu, au bout d'un certain temps, elle considčre que le message est perdu et elle le renvoie ŕ nouveau. Toutefois, dans le cas de grosse quantité de données ŕ transmettre, ce genre de méthode pourrait s'avérer trčs pénalisante pour le débit réel des données. On utilise donc un mode d'envoie par groupe des messages. C'est ŕ dire que l'émetteur et le récepteur s'accordent sur un nombre maximum T de messages transmissibles sans acquittement. L'envoie par le récepteur de l'acquittement Ai puis Ai+K (avec K < T) signifie que tous les messages Mi ŕ Mi+K ont été correctement reçus. De plus, tous les messages n'ont pas une taille leur permettant de tenir en une seule trame. Ils sont donc découpés (ŕ l'origine par paquets de 536 octets mais depuis qu'Ethernet s'est généralisé, on utilise des paquets de 1460 octets). Ce principe, aussi appelé segmentation, transforme les messages en petits paquets, émis par la suite dans des trames IP. Chaque segment dispose d'un numéro de séquence qui permet d'établir une relation avec le segment précédent et le segment suivant. Les segments sont émis en rafale, c'est ŕ dire par groupe, et sont acquittés par groupe. Le phénomčne de création de groupe est appelé fenętrage. Il faut noter que le protocole TCP place systématiquement ŕ 1 le bit Don't Fragment de la trame IP. Il utilise donc un algorithme pour définir la taille maximum de chacun des segments. Entęte TCP
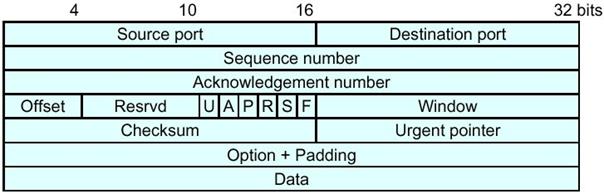
· Les champs Source Port et Destination Port contiennent le numéro du port de la machine source ou destination. Le numéro du port source est dans le cas du client un "ephemeral port" et dans le cas du serveur un "well known port". Inversement pour le port de destination. · Le champ Sequence number contient un nombre "aléatoire" qui représente le numéro du premier octet de la séquence transmise. · Le champ Acknowledgement Number contient un nombre qui est le numéro de l'octet de début de la prochaine séquence ŕ transmettre donc le numéro du dernier octet reçu + 1. · Le champ Offset contient le nombre de mot de 32 bits composant l'entęte TCP. Il indique l'offset par rapport au début de la trame TCP oů on va trouver les données. · Le champ Reserved est composé de 6 bits ŕ 0, il est réservé ŕ un usage futur. · Les 6 bits de contrôle : o URG (U) pour URGENT : les données doivent ętre émises ou reçues immédiatement. o ACK (A) pour ACKNOWLEDGE : la trame est une trame d'acquittement. Le champ Acknowledgement Number est signifiant. Si le bit A n'est pas actif, la valeur du champ Acknowledgement Number n'est pas pris en compte. De męme lorsqu'il est actif, le champ Sequence Number n'est pas pris en compte. o PSH (P) pour PUSH : les données doivent ętre transmise ŕ l'applicatif sans attendre la fin du segment (ce bit est obsolčte, il est utilisé pour signaler la présence de données). o RST (R) pour RESET : réinitialise la connexion (notamment en cas de désynchronisation) o SYN (S) pour SYNCHRONIZE : initie la connexion. Il faut noter que le segment SYN dispose d'un numéro de séquence bien que ne contenant pas de données. Ce numéro est appelé ISN (Initial Sequence Number). o FIN (F) pour FINISH : achčve la connexion (fin de connexion). · Le champ Window donne la taille en octet des données que l'émetteur est capable de recevoir. Dans le cas d'une trame d'acquittement, il s'agit de la taille de la fenętre avant le prochain acquittement. · Le champ Checsum contient un code CRC calculé pour l'ensemble de l'entęte du segment en cours de transmission. Il utilise comme pour UDP un pseudo entęte dont les champs sont rigoureusement les męmes que pour UDP et qu'il place avant l'entęte TCP (le champ proto contient la valeur 6). Pour le calcul du CRC, le champ Cheksum est initialement mis ŕ 0.
Pseudo entęte TCP · Le champ Urgent Pointer contient l'offset du premier octet de données non-urgente dans le segment. Il n'est pris en compte que si le bit U est actif. Les octets, entre le début du segment et la valeur du champ Urgent Pointer, sont donc les octets urgents. · Les options permettent de passer des informations de contrôle de l'émetteur au récepteur. Il peut il y avoir plusieurs options ŕ la suites les unes des autres. Chaque option s'organise de deux façons : o soit sous la forme d'un octet unique, auquel cas, l'octet est complété de 24 bits de bourrage (padding) pour obtenir une chaîne de 32 bits de long. o soit sous la forme d'un groupe d'octet organisé sous la forme : d'un octet de Code, d'un octet de longueur (incluant la taille des octets de code et de longueur) et de plusieurs octets de données. Lŕ encore la taille de l'option devant ętre un nombre entier de fois 32 bits, l'option est complétée par des bits de bourrage. Il existe 7 codes d'options : o Les codes 0 et 1 servent ŕ fabriquer le padding (le code 0 est trčs rare voir inutilisé, seul le code 1 est fréquemment employé). Le code 0 signifie la fin des options (il est placé aprčs des options de taille variable), tandis que le code 1 signifie NOP (No OPeration), il est placé avant les autres options en guise de padding. o Le code 2, pour Maximum Segment Size. Cette option permet lors de l'initialisation de la connexion (lorsque le bit S est actif) de définir la taille maximum du segment admissible. Cette option est donc un groupe d'octet. Le champ longueur valant 4 (pour 4 octets utilisés pour l'option), la taille maximum d'un segment est codée sur 16 bits. o Le code 3, pour modifier la taille de la fenętre au delŕ des 16 bits autorisé par l'entęte TCP. o Les codes 4 et 5, pour autoriser la fonction SACK (Selective Acknoledgment). La taille de cette option est variable. o Le code 8, pour la mesure du RTT (Round Trip Time), le temps mis par un message pour réaliser un aller-retour, ou plutôt son estimation. Il est codé sur 10 octets avec 2 octets de Padding.
Fonctionnement de TCP.Initialisation de la connexionLorsque que l'émetteur souhaite établir une communication avec une cible pour un protocole donné, il commence par créer une socket, donc il sélectionne un port éphémčre qu'il va désormais utiliser pour toutes ses communications avec cette cible avec ce protocole. Il envoie alors une trame SYN en direction de la machine cible. Ce message est identifié par un numéro de séquence spécial le ISN de la machine source, appelons le x.
La machine ŕ l'origine de la requęte SYN reçoit la trame SYN + ACK. Elle répond en retournant une trame ACK avec un numéro de séquence qui vaut x+1 et un numéro d'acquittement qui vaut y+1.
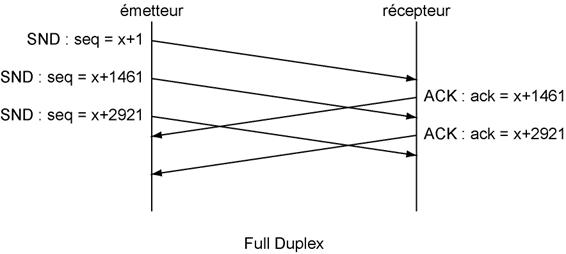
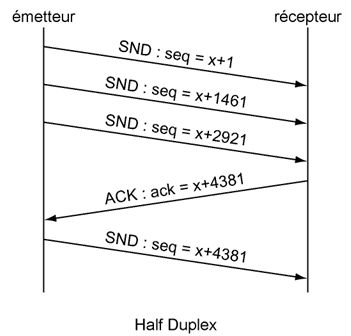
La connexion est maintenant établie. Il faut noter que la mise ŕ 1 du bit S est considérée comme la présence d'un octet de données donc donne lieu ŕ l'incrémentation du numéro de séquence d'une unité. Par contre, la présence du bit A n'influe pas sur le numéro de séquence. DialogueLa connexion étant établie, le dialogue peut prendre place entre l'émetteur et le récepteur. Dans cette conversation, l'émetteur va envoyer des segments et le récepteur va les acquitter. L'utilisation du processus de fenętrage entraîne un comportement variable selon que le Réseau présente des caractéristiques Full Duplex ou Half Duplex. Dans le cas d'un Réseau full duplex, la machine émettrice envoie un premier segment avec un numéro de séquence qui vaut x+1. Une fois ce message émis (en imaginant qu'il a envoyé une trame de 1460 octets), la machine émettrice envoie un autre segment immédiatement avec un numéro de séquence de x+1461.
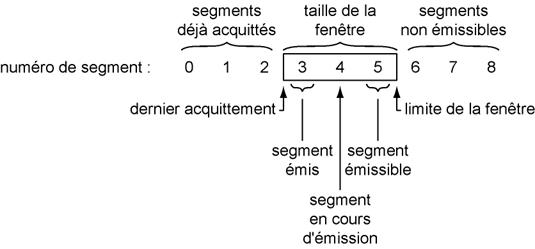
En théorie, durant l'émission de ce second segment, la machine émettrice doit recevoir de la machine réceptrice des données un acquittement du premier segment. Le champ numéro d'acquittement ayant pour valeur x+1461. Dans le cas contraire, en imaginant que le fenętrage autorise l'émission de 3 segments maximum sans acquittement, la machine émettrice est donc encore autorisée ŕ envoyer un nouveau segment avec un numéro de séquence valant x+2921. En suite, elle reste bloquée dans cet état jusqu'ŕ ce que le récepteur acquitte au moins un des segments précédents. Si par exemple elle récupčre une trame d'acquittement valant x+2921, elle en déduit que tous les octets émis dans le premier et dans le second segment ont été acquittés (tous les octets des trames de numéro de séquence x+1 et x+1461). Grâce ŕ ce principe d'acquittement, il est possible de décrire l'agencement des segments comme une fenętre glissante (d'oů le nom de fenętrage). En reprenant les valeurs de l'exemple précédent, on peut établir une représentation du phénomčne :
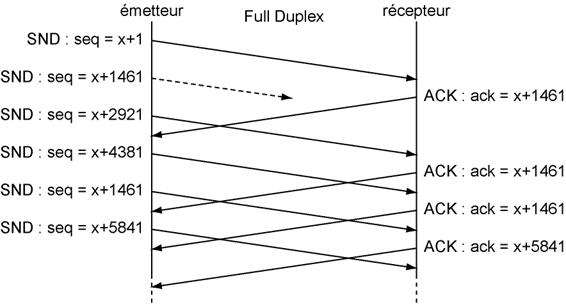
Perte de segment.Toutefois dans certains cas, il se peut qu'un segment soit perdu. Dans ce cas, la machine réceptrice va elle męme signaler cette perte ŕ l'émetteur qui en réaction va renvoyer le segment perdu. Dans le cas d'une liaison Full-Duplex, la transmission de l'acquittement de chaque segment s'effectue avec un léger retard par rapport ŕ la réception du segment. L'émetteur ne s'arrętant pas de transmettre, il va rapidement apparaître un décalage en le numéro de séquence et le numéro d'acquittement.
Les segments reçus par le récepteur pendant l'intervalle de temps compris entre la perte du segment et le segment de remplacement (c'est ŕ dire les deux segments avec un numéro de séquence égal ŕ x+2921 et x+4381) sont mémorisés mais ne sont pas acquittés (le récepteur retournant un numéro d'acquittement égal ŕ x+1461, quel que soit le numéro de séquence du segment reçu). Sitôt le segment manquant reçu, le récepteur valide par la męme occasion les deux segments qu'il a reçu en retournant un numéro d'acquittement égal ŕ x+5841. Précisons toutefois que dans l'exemple précédent, la fenętre utilisée n'est plus de 3 mais de 4 segments. Dans le cas oů l'on utiliserait une fenętre de 3 segments, la machine émettrice aurait dű attendre la réception de l'acquittement numéro x+5841 avant de pouvoir envoyer un autre segment.
Fermeture de la connexion
Il faut noter que la mise ŕ 1 du bit F est considérée comme la présence d'un octet de données donc donne lieu ŕ l'incrémentation du numéro de séquence d'une unité. Par contre, la présence du bit A n'influe pas sur le numéro de séquence. Définition du MSSLe MTU (Maximum Tranfert Unit) est une valeur implantée dans chaque équipement Réseau, il définit en fonction du matériel mis en śuvre, la taille maximale du champ de données. Le MSS (Maximum Segment Size) est obtenu en retirant 40 octets au plus petit MTU des Réseaux traversés. Comme, par définition, le chemin parcouru par chaque segment est susceptible de varier, le MSS est susceptible de varier. Au début, le MSS est donc initialisé ŕ la valeur locale du MTU moins 40. Lors de l'envoie du segment SYN et du retour SYN + ACK, les deux machines en communication se passent l'information concernant leurs MSS respectifs. Une fois cette valeur définie, elle est utilisée pour tous les envois. Si un routeur intermédiaire utilise un MTU inférieur ŕ celui défini lors de l'initialisation, lors de la transmission du premier segment, le routeur retournera une trame ICMP d'erreur (type 3, code 4) ŕ l'expéditeur du segment puisque le bit DF (Don't Fragment) est actif. Le routeur en théorie retourne, dans la trame ICMP, une information supplémentaire sur la valeur du MTU du Réseau ŕ l'origine du problčme. Cette valeur sera alors utilisée par l'émetteur pour l'envoie du segment en échec, et par la męme occasion servira ŕ mettre ŕ jours le récepteur. L'automate TCP
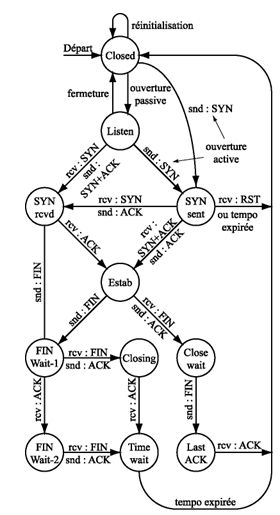
Le fonctionnement de TCP est tellement simple qu'il s'apparente ŕ un fonctionnement de type automate.
Dans le second cas (mode serveur), Notre machine a ouvert une socket. Elle est ŕ l'écoute du Réseau. Lorsqu'elle reçoit un segment SYN, elle répond par SYN + ACK, ce qui la fait passer ŕ l'état SYN received (SYN reçu). Le client en renvoyant un ACK la fait passer ŕ l'état Established (établie). En cas d'attente trop longue entre le SYN+ACK et le ACK, on peut envoyer la commande FIN pour passer ŕ l'état de fermeture active de la connexion (fermeture ŕ notre initiative).
A l'état Established, le transfert de données entre les deux machines a lieu. Une fois ce transfert effectué, la fermeture de la connexion doit avoir lieu. Elle peut, elle aussi ętre active (notre machine est ŕ l'initiative de la fermeture) ou passive (la machine distante est ŕ l'initiative de la fermeture).
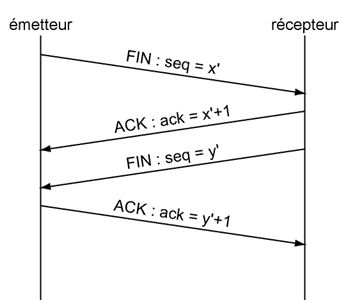
Dans le premier cas, notre machine envoie un segment FIN, qui nous fait passer ŕ l'état FIN wait-1. En réponse, la machine distante retourne un ACK, qui fait passer la machine ŕ l'état FIN wait-2. Puis la machine distante envoie un segment FIN et notre machine lui retourne un ACK. Cela fait passer la machine en mode Time-Wait oů elle va attendre la durée de vie de 2 segments avant de fermer définitivement la connexion.
Dans le second cas (la fermeture passive), la machine distante envoie le segment FIN, notre machine lui répond immédiatement ACK, ce qui la fait passer ŕ l'état CLOSE wait. Puis notre machine envoie un segment FIN qui la fait passer ŕ l'état LAST ACK. La connexion ne sera réellement détruite que lorsque notre machine recevra le ACK de la machine distante.
Il peut arriver que 2 machines aient en męme temps l'idée d'ouvrir ou de fermer une connexion. Dans ce cas, on parle d'ouverture ou de fermeture simultanée.
L'ouverture simultanée se déroule en 6 temps :
1. A envoie un SYN (elle est ŕ l'état SYN sent) 2. B envoie un SYN (elle est ŕ l'état SYN sent) 3. B reçoit le SYN (elle passe ŕ l'état SYN rcvd), elle répond par un ACK. 4. A reçoit le SYN (elle passe ŕ l'état SYN rcvd), elle répond par un ACK. 5. A reçoit le ACK (elle passe ŕ l'état Estab) 6. B reçoit le ACK (elle passe ŕ l'état Estab).
La fermeture se déroule en 8 temps :
1. A envoie un FIN (elle est ŕ l'état WAIT 1) 2. B envoie un FIN (elle est ŕ l'état WAIT 1) 3. B reçoit le FIN (Il passe ŕ l'état CLOSING) 4. B envoie ACK. 5. A reçoit FIN (il passe en mode CLOSING) 6. A envoie ACK 7. A reçoit ACK (il passe en mode Time wait) 8. B reçoit ACK (il passe en mode Time wait) 9. au bout de 2 temps de transmission d'un segment, la connexion est close. Le DNS.En "ignorant" un peu le placement des couches, au profit de la compréhension générale de TCP/IP, il convient de parler du service DNS (Domain Name System). Ce protocole permet d'associer un nom (ou plusieurs) ŕ une adresse IP. Ce service permet une dénomination plus longue mais plus compréhensible des noms des machines. Bien que de trčs nombreuses "dérives" commerciales soient ŕ noter, ce service permet en principe de retrouver naturellement l'adresse IP de la machine cible grâce ŕ une machine spéciale, le serveur de DNS. Son principe consiste pour la machine source ŕ lancer des requętes vers un serveur de DNS qui lui interroge sa table interne en vue de réaliser une traduction entre le nom donné et une adresse IP. Les noms DNS n'étant pas centralisée sur une machine (les serveurs de DNS ne connaissent pas toutes les machines de la plančte) mais distribuée (chaque serveur de DNS ne connaît que les machines du domaine dont il a la charge), il existe des procédures permettant de répondre męme si la machine lui est inconnue. Les tables DNS sont des tables statiques souvent couplées ŕ des caches qui eux sont gérés dynamiquement (l'absence de sollicitation vers un domaine entraîne son élimination du cache, au contraire, des sollicitations répétées vers une machine la rendent quasi permanente). Lorsqu'une requęte portant sur un domaine inconnu arrive ŕ un serveur, celui ci, pour effectuer la résolution du nom, peut soit utiliser une approche récursive, soit une approche itérative. Formalisme DNS.Le formalisme du nom DNS utilise des racines géographiques comme .fr ou .de (Deutchland) ou .uk (United Kingdom), etc. Oů des racines fonctionnelles comme .mil (militaire) ou .com (commercial) ou .gov (gouvernemental) etc. Pour servir de base ŕ l'arbre dans lequel on va créer des domaines donnant éventuellement accčs ŕ d'autres sous-domaines. Tous, domaines et sous-domaines sont composés de machines qui peuvent ętre nommées et męme surnommées. Ainsi la machine : www.iut-cachan.u-psud.fr est en fait : · une machine dont le nom est : www, · placée sur le sous-domaine : iut-cachan, · qui est lui męme un élément du domaine : u-psud, · qui est sur la racine fr. Comme il est assez rare de donner pour nom ŕ une machine "www", il s'agit en fait d'un surnom qu'une machine s'est vue attribuée. On parle alors d'alias. Mieux encore, 2 machines peuvent avoir le męme nom (et męme dans certains cas, la męme adresse IP) si elles ne fournissent pas les męme services, par exemple, un serveur de courrier peut avoir le męme nom qu'un serveur www si tousles 2 sont spécialisés et si l'on est capable de router l'information différemment en fonction du service. Approche itérativeDans le cas d'une approche itérative, le serveur local qui a reçu en premier la requęte se charge (s'il ne connaît pas la cible) d'interroger un serveur "supérieur", en "généralisant" au fur et ŕ mesure sa recherche. Prenons l'exemple d'une machine du domaine .iut-cachan.u-psud.fr qui cherche ŕ contacter la machine www.iut-velizy.uvsq.fr. · La machine lance une requęte auprčs de son serveur de DNS (on l'appellera A). · Si A ne connaît pas la machine cible, il contacte alors le serveur de DNS du domaine supérieur, c'est ŕ dire le serveur du domaine .u-psud.fr. · A interroge donc le serveur DNS de ce domaine. S'il ne connaît pas la machine cible, il transmet ŕ A l'adresse du serveur DNS de la racine .fr. · A interroge le serveur DNS de la racine .fr. Ce dernier, męme s'il ne connaît pas la machine cible, connaît, en revanche, le serveur DNS du domaine .uvsq.fr. Il transmet donc l'adresse de cette machine ŕ A. · A interroge alors le serveur DNS du domaine .uvsq.fr, si celui-ci ne connaît pas la machine cible, il connaît le contrôleur du domaine .iut‑velizy.uvsq.fr dont il transmet l'adresse ŕ A. · A interroge le contrôleur du domaine .iut-velizy.uvsq.fr qui lui retourne l'adresse de la machine cible. Approche récursive.Dans une approche récursive, chaque serveur transmet la requęte au serveur du niveau supérieur et ainsi de suite. Dans notre exemple de tout ŕ l'heure, cela donne : · Le serveur du domaine .iut-cachan.u-psud.fr demande au serveur .u‑psud.fr si il connaît la machine www.iut-velizy.uvsq.fr. · Le serveur du domaine .u‑psud.fr transmet la demande au serveur du domaine .fr. · Le serveur du domaine .fr transmet la demande au serveur du domaine .uvsq.fr. · Le serveur du domaine .iut-velizy.uvsq.fr identifie la machine cible et retourne au serveur .uvsq.fr l'information. · Le serveur .uvsq.fr retourne l'information au serveur .fr et ainsi de suite jusqu'ŕ ce que l'information soit retournée ŕ la machine d'origine.
|


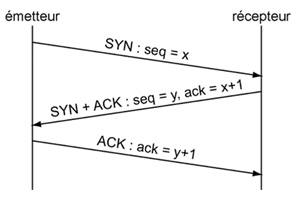 La machine cible reçoit le message SYN et lui répond en envoyant un message SYN
+ ACK. Le numéro de séquence de cette réponse est l'ISN de la machine (appelons
le y). Le numéro d'acquittement est le numéro de séquence reçu plus 1 (x+1).
La machine cible reçoit le message SYN et lui répond en envoyant un message SYN
+ ACK. Le numéro de séquence de cette réponse est l'ISN de la machine (appelons
le y). Le numéro d'acquittement est le numéro de séquence reçu plus 1 (x+1).