Etude de quelques Rťseaux locaux
Dans ce chapitre, nous allons (enfin) ťtudier le fonctionnement de quelques Rťseaux. En particulier, il me semble logique de vous parler d'ETHERNET + TCP-IP, de CAN et de I2C. Bien entendu, ce chapitre n'est pas exhaustif, et ne pourrait pas l'Ítre. En effet, le renouvellement quasi permanent des technologies ne le permettrait pas.
Mais avant de prťsenter ces Rťseaux, nous allons regarder un petit lexique des diffťrents Rťseaux disponibles sur le marchť.
Il faut noter que bon nombre de Rťseaux ne sont que des variantes des Rťseaux les plus connus (ce qui ŗ tendance ŗ rendre l'offre encore plus difficile ŗ analyser), on retiendra pour l'exemple FIPIO qui est une version SENSOR BUS de FIP et FIPWAY la version DEVICE BUS. Mais les exemples ne s'arrÍtent pas lŗ puisque certains Rťseaux (comme CAN ou FIP, considťrťs comme des technologies), sont utilisťs comme des "supports" pour des applications, ce qui fait qu'entre 2 Rťseaux basťs sur CAN, il n'y a souvent que la couche 7 (couche d'application) qui les rend incompatible (par exemple SDS, DEVICENET, VAN et CAL ne sont que des applications spťcifiques de CAN pour un type de fonctionnement prťcis).
Ce genre de rťcupťration est assez intťressante puisqu'elle autorise l'utilisation de systŤmes CAN tout en les rendant plus spťcifique donc plus adaptable.
TCP/IP.
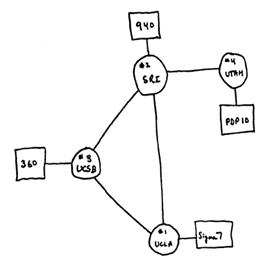
C'est en 1957 que le "Department Of Defence" (le ministŤre de la dťfense amťricain) en rťponse au vol du premier Sputnik soviťtique, initie le projet DARPA (Defence Advanced Research Project Agency) pour permettre aux USA de reprendre le leadership dans les domaines technologiques (accessoirement), mais surtout militaire.
L'idťe de mettre en úuvre un Rťseau "invulnťrable" aux attaques nuclťaire soviťtiques apparaÓt trŤs tŰt comme un concept fondamental pour lequel le DARPA va financer la recherche en lanÁant le projet qui deviendra ARPANET.
C'est aussi en 1969 que Steve Crocker publie la premiŤre RFC (Request For Comment). Les RFC sont les moyens d'ťchanger des informations ou de dťcrire des procťdťs, voir de rťsumer des connaissances. Il arrivera que l'usage dťvie (voir la RFC 527).
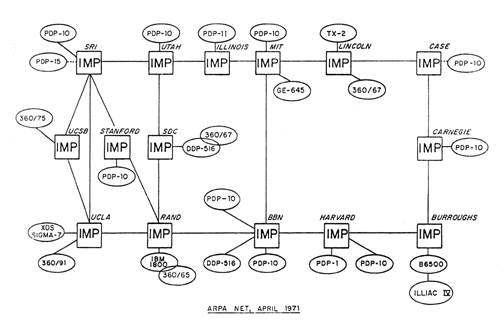
En 1970, ARPANET choisi le protocole NCP (Network Control Protocol) pour le routage des paquets. En 1971, ARPANET est composť de 15 núuds. Les protocoles FTP (File Transfert Protocol) et Telnet sont crťťs par le Network Working Group.
Le premier programme permettant d'envoyer des E-mail apparaÓt (SENDMSG), mais c'est en 1972 que le @ est choisi comme sigle de ponctuation entre l'utilisateur et l'adresse.
En 1972, ARPANET est composť de 30 núuds. Le trafic sur ARPANET est composť ŗ 75% d'E-mail. Le NWG devient le INWG (International NWG). En France, Louis Pouzin dťveloppe l'ARPANET franÁais sous le nom de CYCLADES.
En 1973, ARPANET devient international avec le raccordement du University College of London et le NORSAR organisme Norvťgien de communication. ALOHANET est le premier Rťseau sans fil, il relie 7 supercalculateurs sur 4 Óles de l'archipel de HawaÔ. ARPANET est composť de 40 núuds.
En 1974, Vinton Cerf et Robert Kahn prťsentent le protocole TCP/IP. Le trafic quotidien sur ARPANET dťpasse les 3 millions de paquets.
En 1975, ARPANET est composť de 61 núuds et la NSF (National Science Foundation) commence ŗ financer le projet. SENDMSG se change en MSG, le premier logiciel E-mail complet (lecture, transfert, rťponse). C'est aussi ŗ cette date que le premier Newsgroup est crťť, il parle de science fiction, Einar Stefferud en est le premier modťrateur. En 1979, DARPA et NSF commencent ŗ ťtudier la possibilitť de crťer le CSNET (Computer Science research Network), mais le coŻt de 3 millions de dollars est jugť prohibitif. Naissance de USENET (les newsgroup automatisťs). Kevin MacKenzie crťe les premiers ťmoticons (J L). En 1981, le CSNET est crťť pour les universitaires non reliťs ŗ ARPANET, il est financť par la NSF. En France on voit apparaÓtre le Minitel. En 1982, L'ensemble des Rťseaux mondiaux commence leur migration en abandonnant le protocole NCP au profit de TCP/IP. La NorvŤge est la premiŤre ŗ effectuer cette opťration. TCP/IP est reconnu comme le standard international de communication en Packet Switched. En 1983, NCP disparaÓt. L'Europe se connecte (Hollande, SuŤde, NorvŤge, Angleterre, Allemagne) ŗ EUNET (European UNIX Network) version europťenne de CSNET qui permet le transfert d'E-mail et l'utilisation de USENET. PremiŤre version des services de nom qui permettent de traduire un nom de machine en adresse IP et inversement. Aux USA, ARPANET se sťpare en MILNET (Rťseau exclusivement militaire) et ARPANET (Rťseau civil). Le nouveau ARPANET est connectť ŗ CSNET. En 1984, le Japon crťe JUNET, la version asiatique de CSNET. Le Canada fait de mÍme avec NorthNet. L'ensemble du Rťseau contient plus de 1000 núuds. Le DNS est adoptť comme service de nom. L'URSS implťmente une version russe d'USENET En 1985, le 1er mars la racine .com est crťťe vont suivre : .edu, .gov et .org en juin et .uk en juillet. En 1986, la NSF crťe NSFNET sur un backbone ŗ 56 Kbit/s, regroupant 5 supercalculateurs. Le protocole NNTP (News Network Transfert Protocol) est crťť. En 1987, plus de 10 000 núuds sont connectťs aux Rťseaux mondiaux. Plus de 1 000 RFC ont ťtť crťťes. 1988 : Naissance du mot Internet lors de la connexion de 7 nouveaux pays (Canada, Danemark, Finlande, France, Islande, NorvŤge et SuŤde) au Rťseau NSFNET qui fťdŤre dťjŗ les Rťseaux amťricains. Le 2 novembre, le premier virus Rťseau (worm) est officiellement dťclarť. Il infecte ŗ peu prŤs 6 000 des 60 000 núuds connectťs ŗ internet. Naissance du IANA (Internet Assigned Number Autority) qui contrŰle les adresses IP et les numťros de ports TCP (et UDP). Sa direction est confiťe ŗ John Postel. Naissance aussi du protocole IRC. 1989 : Internet dťpasse les 100 000 núuds avec la connexion de 10 nouveaux pays ŗ NSFNET (Allemagne, Angleterre, Australie, Hollande, IsraŽl, Italie, Japon, Mexique, Nouvelle Zťlande et Porto Rico). NSFNET utilise des lignes T1 (1,544 Mbit/s) 1990 : Disparition de ARPANET et arrivťe de 11 nouveaux pays sur NSFNET (Argentine, Autriche, Belgique, Brťsil, Chili, Corťe, Espagne, GrŤce, Inde, Irlande et Suisse) En 1991, NSFNET accueille 10 nouveaux pays (beaucoup du bloc de l'Est puisque le mŻr viens de tomber) sur ses nouvelles lignes T3 (44,736 Mbit/s). Au CERN ŗ GenŤve Tim Berners-Lee crťe le World Wide Web en dťveloppant le protocole HTTP (Hyper Text Transfert Protocol). Le premier site Web au monde est http://info.cern.ch. NSF recense un trafic mensuel de 1012 octets (1000 milliards). La NSF autorise un usage commercial d'internet. "World comes On Line" est le premier fournisseur d'accŤs ŗ internet. En 1992, 13 nouveaux pays rejoignent NSFNET (dont la Russie). Il y a plus de 1 000 000 de núuds connectťs ŗ internet. En 1993, 17 nouveaux pays rejoignent NSFNET. Le premier navigateur Web (Mosaic) apparaÓt. La croissance du service http est de 341 634% sur l'annťe. Naissance des moteurs de recherche. En 1994, Le trafic mensuel sur Internet dťpasse les 1013 octets (dix mille milliards d'octet). Premier spam (envoi de courrier en masse) par une sociťtť d'avocat de l'Arizona. 22 pays rejoignent NSFNET (dont la Chine). Apparition des premiŤres publicitťs sur internet. AOL et Compuserve sont les principaux FAI (Fournisseur d'AccŤs ŗ Internet). En 1995, NSFNET redevient un Rťseau de recherche, les fournisseurs d'accŤs ŗ internet ne transitent plus sur NSFNET. Le service http dťpasse en quantitť le service FTP. 22 nouveaux pays rejoignent l'internet. En 1996, les backbone ont des dťbits variant entre 155 et 622 Mbit/s. 29 nouveaux pays rejoignent internet (on peut noter que la Guadeloupe est dans cette liste avec l'extension .gp). Les piratages se multiplient (NASA, CIA, Air Force,Ö). En 1997, le 2 000Ťme RFC est publiť. 47 nouveaux pays rejoignent internet. Il y a plus de 100 000 serveurs de noms. En 1998, PremiŤre fÍte de l'internet (20 et 21 mars) sous l'initiative de Jack Lang. L'internet compte 43 230 000 clients. DťcŤs de John Postel. Aujourd'hui (le 01/01/2004), on recense plus de 200 000 000 de núuds.
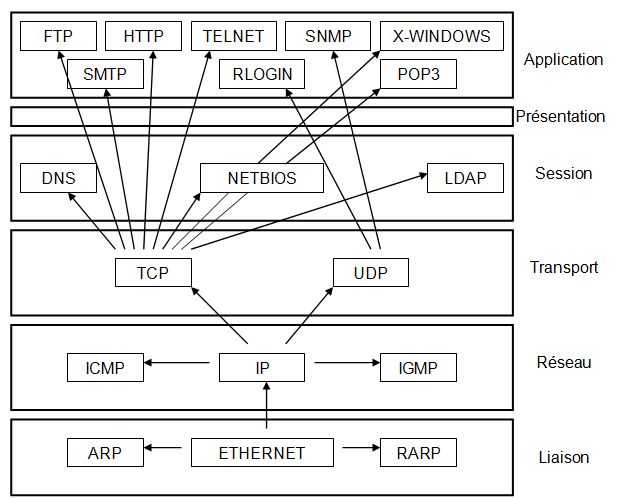
Prťsentation du modŤle OSI adaptť ŗ quelques ťlťments de la suite TCP/IP.
Le protocole IP.
Le protocole IP a pour rŰle de router l'information, c'est ŗ dire de permettre le transport des informations d'un Rťseau vers un autre ŗ travers plusieurs routeurs, donc dťpasser la couche 2 pour franchir le mur du routeur, et atteindre sa cible en prenant le plus court chemin. Pour cela on utilise un nouveau format d'adressage, l'adresse IP.
L'adresse IP est composťe, comme on le verra plus loin, de 32 bits, mais pour en simplifier l'usage (on pourra juger cette simplification un peu trop "informaticienne") on a regroupť ces termes par octet et ťnumťrť l'adresse en dťcimal pointť (4 nombre dťcimaux infťrieurs ŗ 255 et sťparťs par des points).
On trouve cette adresse encapsulťe dans la trame Ethernet (dans les premiers octets du champ de donnťe de la trame IEEE 802.3). Elle est placťe ŗ l'intťrieur de l'entÍte IP
EntÍte IP
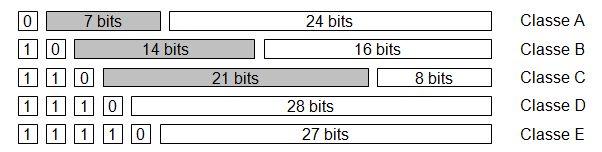
L'adresse IP est dťfinie par un ensemble de 4 octets. Ce qui permet de dťfinir 232 adresses (4 300 milliards de núuds). Ces adresses sont rangťes selon 5 classes, dťpendant de la valeur des premiers bits de líadresse.
∑ La classe A permet de crťer 126 Rťseaux de 224 machines (16 millions), soit une utilisation des adresses de 1.0.0.0 ŗ 126.255.255.255. ∑ La classe B permet de crťer 16 384 Rťseaux de 216 machines (65 536), soit une utilisation des adresses de 128.1.0.0 ŗ 191.255.255.255. ∑ La classe C permet de crťer 221 Rťseaux (2 millions) de 256 machines, soit une utilisation des adresses de 192.0.1.0 ŗ 223.255.255.255. ∑ La classe D permet ŗ une seule trame IP de síadresser ŗ plusieurs machines (MULTICAST mais en IP), elle utilise les adresses comprise entre 224.0.0.0 et 239.255.255.255. ∑ Enfin la classe E est rťservťe ŗ de futures utilisations, elle utilise quand mÍme les adresses comprises entre 240.0.0.0 et 247.255.255.255. Cette rťpartition permet aussi de dťfinir non seulement une "arborescence" du nombre de Rťseau, mais aussi une organisation hiťrarchique.
Au niveau de la classe A, toutes les machines sont des routeurs ou des passerelles interconnectťes sur un faible nombre de Rťseaux. On forme ŗ ce niveau les interconnexions des grands Rťseaux intercontinentaux.
Au niveau de la classe C, on retrouve un petit nombre d'ordinateurs connectťs sur un grand nombre de sous-Rťseaux (sous Rťseaux pilotťs par les routeurs de la classe A et B). On est ici dans le domaine "grand-public" avec plein de petits Rťseaux sur lesquels sont connectťs les machines des utilisateurs.
On arrive ainsi ŗ la reprťsentation suivante des adresses IP :
En gris, le codage du "nom" du Rťseau, en blanc le codage du "nom" de la machine.
Pour permettre ŗ une machine de s'identifier correctement dans son environnement, un autre paramŤtre que son adresse IP lui est indispensable, c'est le masque de sous-Rťseau. Cette valeur composťe de 4 octet lui permet de dťfinir l'adresse du Rťseau sur lequel elle est connectť, et par dťduction connaÓtre son "nom" sur le Rťseau.
Par exemple, pour une machine d'adresse IP de classe C :
Attention, les nombres prťcťdents sont prťsentťs en base 10, pour mieux comprendre la manipulation prťsentťe dans cet exemple de traduire les nombres en hexadťcimal.
Analysons maintenant, ligne par
ligne un entÍte IP.
∑
Les 4 premiers bits dťfinissent le numťro de version IP,
gťnťralement ce nombre est 4 (IPv4).
∑
Le champ IHL (Ip Header Length) donne le nombre de mots de 32 bits
contenu dans l'entÍte (les donnťes n'en font pas partie), mais en incluant les
options et le Padding. ∑ Le champ TOS (Type Of Service) est en rťalitť composť de 5 sous ensembles. ∑ Les 3 premiers bits forment un ensemble qui code la prioritť du message. ∑ 000 : routine (normal) ∑ 001 : priority ∑ 010 : immediate ∑ 011 : flash ∑ 100 : flash override ∑ 101 : critic ∑ 110 : internetwork control ∑ 111 : network control ∑ Le bit suivant est ŗ 0. ∑ Les 4 derniers bits servent ŗ dťcrire le service demandť. Ils sont exclusifs (un seul bit peut Ítre validť pour une trame) ∑ D : Minimiser le dťlai, utilisť pour les messages de commande ou de synchronisation, donc pour des messages de petite taille. ∑ T : Maximiser le dťbit, bien entendu, cette option est utilisťe dŤs qu'il y a beaucoup de donnťes ŗ transmettre. ∑ R : Maximise la fiabilitť, spťcialement utilisťe par les opťrations de gestion du Rťseau. ∑ C : Minimise le coŻt, en gťnťrale non utilisťe. Le Champ TLF (Total Length Field) permet de fixer la taille totale du paquet IP (donc, connaissant la taille de l'entÍte, on connaÓt la taille du champ de donnťes). Ce champ permet ainsi d'ťliminer des termes de bourrage utilisť pour porter les petites trames IP au format minimum de la trame Ethernet (46 octets). ∑ Le champ d'identification donne un numťro unique ŗ chaque datagramme d'une machine, ce numťro s'incrťmente de 1 aprŤs chaque ťmission. Il permet ainsi de connaÓtre le numťro d'ordre de chaque datagramme transmis. En cas de fragmentation d'un datagramme, le numťro d'identification est dťdoublť pour Ítre le mÍme sur tous les fragments d'un mÍme message.
∑ Les 3 bits de Flag permettent de contrŰler les fragmentations.
∑ "More Fragments" permet de prťvenir que d'autres fragments d'un mÍme datagramme sont ŗ suivre. Le dernier fragment du datagramme a forcťment ce bit ŗ "0" (No more Fragment). ∑ "Don't Fragment" permet d'interdire la fragmentation du data-gramme (cela peut entraÓner des erreurs dans la mesure oý la taille maximum du message autorisťe par les couches infťrieures du Rťseau est infťrieure ŗ la taille du datagramme). ∑ Le dernier bit de Flag n'est pas utilisť, donc ŗ 0.
∑ Le champ Fragment Offset permet de dťfinir le "numťro d'ordre" du fragment, chaque fragment pouvant Ítre routť indťpendamment des autres il peut passer par un chemin plus court que son prťdťcesseur et donc arriver ŗ destination avant lui. La machine cible se chargeant alors de recomposer le datagramme en replaÁant les fragments (qui ont la mÍme identitť) dans le bon ordre (ordre croissant des Fragment Offset).
Attention la fragmentation est une arme ŗ double tranchant car si un fragment est perdu, tout le message est ŗ retransmettre.
∑ Le champ TTL (Time To Live) permet de fixer le nombre maximal de routeur qu'un datagramme peut traverser. Ce champ est initialisť ŗ une certaine valeur au dťpart. Puis chaque routeur traversť le dťcrťmente. Arrivť ŗ 0, le datagramme est rejetť, et l'ťmetteur prťvenu. Contrairement ŗ ce que l'on peut croire, cette mťthode n'est pas coercitive, mais permet d'ťliminer des paquets perdus sur le Rťseau.
∑ Le champ protocole permet de dťfinir quel type de service (TCP, UDP, etc.) utilise le champ de donnťes de IP pour y encapsuler ses donnťes. On peut noter certaines valeurs de ce champ (1 pour ICMP, 6 pour TCP et 17 pour UDP)
∑ Le champ HCS (Header Check Sum) contient un code CRC permettant de valider l'entÍte IP et exclusivement l'entÍte IP encapsulť dans la trame Ethernet. Il faut noter que le propre champ HCS est lui mÍme inclus dans l'entÍte, donc dans le champ de contrŰle, pour cela on le considŤre pour le calcul valant zťro.
∑ Enfin, on prťsente les adresses IP de la source et du destinataire, puis, avant d'empiler les donnťes, on laisse systťmatiquement 32 bits libres pour la dťfinition d'options (si il y en a) ou pour un usage ultťrieur. La fragmentation des datagrammes.
Le principe de la fragmentation des datagrammes repose sur la connaissance par chaque routeur de la taille maximum admissible du champ de donnťe de chacun des Rťseaux qu'il interconnecte. Cette valeur communťment appelťe MTU (Maximum Transfert Unit) est dťfinie pour chaque Rťseau.
Lorsqu'une trame arrive sur un routeur, si sa taille dťpasse le MTU du Rťseau sortant, la trame est fragmentťe. Chaque fragment dispose alors du mÍme identificateur que le message d'origine, mais les 12 bits du champ Fragment Offset contiennent le dťplacement par rapport ŗ l'origine du champ de donnťes du message, divisť par 8. La trame IP contient donc toujours un champ de donnťe dont la taille est divisible par 8.
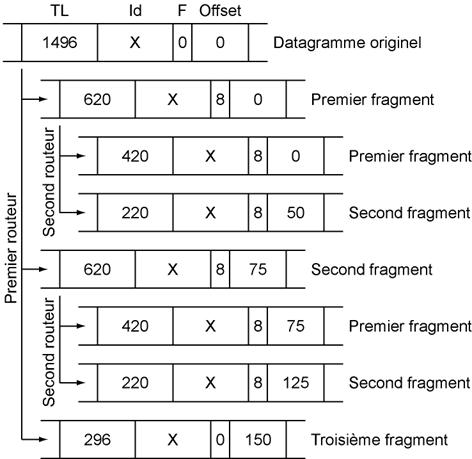
Par exemple, soit 3 Rťseaux reliant la machine A ŗ la machine B, le premier avec un MTU de 1500 octets, le second un MTU de 620 octets et le troisiŤme un MTU de 420 octets.
Un paquet IP de 1496 octets (la taille doit Ítre divisible par 8) est envoyť par la machine A, ŗ destination de la machine B. Il contient 20 octets d'entÍte et 1476 octets de donnťes.
Au passage du premier routeur, ce datagramme est divisť en trois morceaux respectivement de 620 (20 octets d'entÍte et 600 octets de donnťes), 620 et 296 octets. Au total, on a bien un champ de donnťes de 600 + 600 + 276 = 1476 octets.
∑ Pour le premier datagramme, l'entÍte IP est composť de l'identificateur du message d'origine, le bit More Fragment est ŗ 1 et l'offset est ŗ 0. Sa taille est de 620 octets (20 octets d'entÍte et 600 octets de donnťes). ∑ Pour le second datagramme, l'entÍte IP est composť de l'identificateur du message d'origine, le bit More Fragment est ŗ 1 et l'offset vaut 75 (8 x 75 = 600). ∑ Pour le troisiŤme datagramme, l'entÍte IP est composť de l'identificateur du message d'origine, le bit More Fragment est ŗ 0 et l'offset vaut 150.
Au passage par le second routeur, le MTU passe ŗ 420. Cela signifie que les trames doivent Ítre re-fragmentťes. Pour les 2 premiers fragments, le routeur va les re-fragmenter en 2 morceaux respectivement de 420 octets (20 octets d'entÍte et 400 octets de donnťes) et de 220 pour le second.
∑ Pour les fragments de 620 octets : o Le premier fragment (de 420 octets) conserve l'entÍte du fragment prťcťdent. o Le second fragment (de 220 octets) prťsente lui un offset de 50 (8 x 50 = 400) en plus de celui du fragment dont il est issu. ∑ Pour le fragment de 296 octets, sa taille ťtant infťrieure au MTU, il est transmis tel quel sur le Rťseau.
Au total, la machine B va recevoir les 5 fragments du message d'origine. Elle va recomposer le datagramme ŗ partir des offset de fragmentation. Il n'y a pas de discontinuitť, les fragmentations coÔncident.
Dans certain cas, il peut arriver que le datagramme IP soit plus petit que le format minimum du champ de donnťe du Rťseau qui encapsule, on utilise alors les 2 champs de l'entÍte IP (IHL et TLF) pour dťfinir le format rťel du datagramme, et on accole au datagramme des bits de remplissage pour complťter la trame.
Les options de la trame IP.
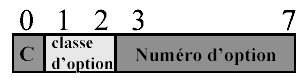
La trame IP peut contenir des options. Celles-ci servent ŗ la mise au point des Rťseaux. Elles restent toutefois optionnelles bien que devant Ítre implťmentťes par tous les ťlťments d'un Rťseau. Les options sont dťcrites par un simple octet.
Le premier bit de l'octet est l'indicateur de copie, il permet de signifier si les informations concernant cette option doivent Ítre copiť pour chacun des ťventuels fragments (bit ŗ 1) ou pas (bit ŗ 0).
Les 2 bits suivants dťfinissent la classe de l'option : o 00 : classe de contrŰle o 01 : rťservť ŗ un usage futur o 10 : mise au point et mesure o 11 : rťservť ŗ un usage futur
Les 5 derniers bits dťfinissent l'option.
Le IANA gŤre bien entendu ces numťros.
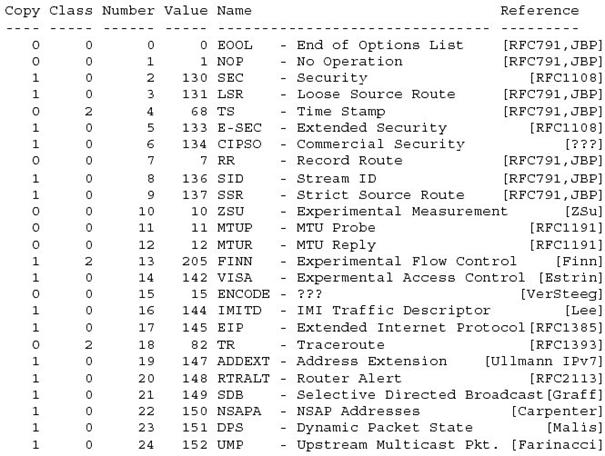
On peut noter en particulier les options suivantes :
∑ L'option 7 est utilisťe pour enregistrer le chemin parcouru. ∑ Les options 9 et 3 permettent de fixer, pour l'option 9 l'intťgralitť du chemin que doit parcourir le message et pour l'option 3 (routage l‚che par la source) les points de passage obligatoires pour un paquet. ∑ L'option 4 (de classe 2) permet de crťer un horodatage des paquets. A chaque passage par un routeur une information horaire est ajoutťe ŗ la trame.
Les options n'utilisant qu'un seul octet pour leur dťfinition, on ajoute systťmatiquement des octets de remplissage pour complťter le paquet de 4 octets commencť par la dťfinition de l'option. On parle alors de PADDING. IP et Ethernet.
L'utilisation du protocole IP sur internet impose la dťfinition de deux problŤmes, d'une part oý et comment se rangent les donnťes et l'identification de la trame IP (au sens physique), d'autre part comment on associe le fonctionnement des 2 protocoles (au sens logique).
Lors de l'ťmission d'une trame
Le protocole IP et le protocole Ethernet sont liťs l'un ŗ l'autre par une table d'ťchange nommťe table ARP (pour Adress Resolution Protocol). Le rŰle de cette table est d'associer ŗ une adresse IP une adresse MAC. Ceci se fait suivant une procťdure trŤs simple.
Les 3 paramŤtres qui doivent Ítre dťfinis pour toutes les machines utilisant IP sont respectivement : l'adresses IP, le masque de sous Rťseau et l'adresse IP de sa passerelle (qui doit Ítre sur le mÍme Rťseau physique que la machine).
Lors de l'ťmission d'une trame IP, la machine source compare l'adresse IP de la machine cible avec l'adresse de son sous Rťseau.
Si elle ne reconnaÓt pas alors l'adresse de son propre Rťseau, elle sait que seule la passerelle est ŗ mÍme de faire transiter son message sur le Web, elle va donc essayer de contacter sa passerelle. Pour se faire, elle va utiliser la mÍme procťdure que celle lui permettant de contacter une machine sur le mÍme sous Rťseau.
Si la cible est sur le mÍme sous Rťseau, en considťrant que la machine source est restťe inactive assez longtemps, elle doit alors associer ŗ l'adresse IP de sa cible une adresse au niveau de la couche MAC (IP n'est pas un Rťseau, rappelez vous ce que j'en ai dit, seul la couche MAC donne accŤs ŗ la liaison physique). Pour identifier l'adresse de sa cible, la machine source envoie une trame ARP Request.
La trame ARP utilise le champ de donnťe de la trame du Rťseau local pour prťsenter son entÍte et place dans le champ de dťfinition du type de trame encapsulť le code hexadťcimal 0806.
EntÍte ARP.
La trame ARP Request envoie alors un message ŗ toutes les machines (BROADCAST ALL) leur demandant de rťpondre ŗ l'ťmetteur si leur adresse IP est prťsente dans la trame. La machine concernťe rťpondra par une trame ARP Reply directement adressťe ŗ l'ťmetteur de la requŤte. L'entÍte ARP est composť de 2 type de champs, d'une part des champs orientťs vers la couche physique (HARDWARE) d'autre part les champs orientťs vers la couche IP (PROTOCOL). Tout commence par 4 octets dťfinissant respectivement pour les 2 premiers le type de couche MAC utilisťe (Ethernet est caractťrisť par un 1), et pour les 2 derniers le type de couche Rťseau utilisťe (on utilise le code 0x0800 pour IP). Les champs Hlen et Plen dťfinissent respectivement la taille en octets des adresses de la couche MAC (6 pour Ethernet) et celles de la couche Rťseau (4 pour IP). Le champ OP indique s'il s'agit d'une requÍte ou d'une rťponse ARP (1 pour une requÍte et 2 pour une rťponse) ou d'une commande RARP (Reverse Adress Resolution Protocol). Les champs prťcisťs par la suite sont respectivement l'adresse MAC de la source, puis son adresse dans la couche Rťseau en suite viennent les adresses MAC et Rťseau de la cible. Lors de la requÍte, le champ correspondant ŗ l'adresse MAC de la cible est laissť vide. Lors de la rťponse, c'est la machine qui ťtait la cible qui devient la source donc c'est elle qui fournit les valeurs d'adresse source et d'adresse cible au niveau de la couche Rťseau, comme au niveau de la couche MAC. La machine cible ťtant alors la machine qui a ťmis la requÍte. Ces donnťes sont alors stockťes dans une table dynamique (qui s'efface si on ne la rafraÓchit pas au bout de 30 secondes). Ainsi, on efface automatiquement les donnťes entrťes dans la table si elles ne sont plus utilisťes.
Gestion des erreurs de routage sous IP.
L'utilisation de IP nous dťcouple des Rťseaux physiques, il faut donc ťtablir une liaison entre les erreurs de routages (gťrťes au niveau de IP) et le comportement du Rťseau (gťrť par la couche MAC). Si une machine cible (par exemple aux USA) est ťteinte, la machine source (par exemple en France) doit recevoir une erreur de routage si elle tente d'y accťder. Pour cela, il existe un protocole (que beaucoup considŤrent comme partie intťgrante de IP) qui se nomme ICMP (Internet Control Message Protocol ou protocole des messages de contrŰle sur internet), qui s'encapsule dans les trames IP. Il a pour rŰle de transmettre les messages d'erreurs liťs ŗ la couche IP au travers des diffťrents Rťseaux.
EntÍte ICMP
Seule la premiŤre ligne de l'entÍte est gťnťralisťe, les lignes suivantes ne sont utilisťes que pour certaines fonctions. On trouve, dans le tableau de la page suivante le contenu des 2 premiers champs (Type et Code) et on associe ŗ ces 2 valeurs une erreur ou une fonction de test. Le 3Ťme champ de la premiŤre ligne de l'entÍte ICMP est le champ de contrŰle d'erreur liť ŗ l'entÍte (CRC).
L'utilisation d'ICMP permet de tester ou de signaler les erreurs, on a donc ťtablis un ensemble de fonction permettant des tests simples. Parmi ces commandes on trouve la commande PING et la commande TRACEROUTE. La commande PING.
La commande PING vient de Packet INternet Groper, elle permet de tester la rťponse d'une machine cible ŗ une sollicitation de la part d'une machine source. Cette sollicitation est un ťcho que la machine cible doit retourner. L'entÍte ICMP est alors composť des 2 premiŤres lignes (8 premiers octets), c'est ŗ dire qu'en plus des champs de type et de code ainsi que celui de checksum, on trouve 2 autres champs. Un champ d'identification qui transmet l'identitť de la source (au cas oý plusieurs sources tenteraient de communiquer avec la mÍme cible en mÍme temps), et un champ de numťro de sťquence qui sert ŗ indiquer quel est le numťro du message transmis. Le message ťmis est donc composť d'un entÍte IP avec l'adresse de la machine source et de la machine cible, en suite on trouve, encapsulť dans le champ de donnťs de IP l'entÍte ICMP qui possŤde un type et un code ŗ 0, suivent un code d'identification de la machine source et le numťro de sťquence. Le message renvoyť par la cible est lui aussi composť d'un entÍte IP et d'un entÍte ICMP oý le type vaut 8 et le code vaut 0, le champ d'identification et le numťro de sťquence sont ceux de la requÍte d'ťcho (le message ťmis).
La commande TRACEROUTE.La commande TRACEROUTE est une implťmentation de la commande PING, elle permet de dťfinir le chemin suivit par le datagramme IP. Son principe est de crťer volontairement des erreurs de routage, pour recevoir les trames d'erreur ICMP. La commande utilisťe est : TRACEROUTE <nom de la machine> Il y alors ťmission d'une trame de type PING ŗ destination de la machine dťclarťe, mais cette trame ŗ un TTL ŗ 0, le premier routeur rťcupťrant une trame dont le contenu ŗ expirť renvoie vers l'ťmetteur une trame ICMP d'erreur. Cette trame ICMP, dont le contenu est un type 11 (dťlai expirť) et un code 0 ou 1 (cela n'a pas d'importance), contient une deuxiŤme ligne nulle (pas d'identification ni de numťro de sťquence), mais sur les lignes suivantes, on trouve le nom de la machine qui a signalť l'erreur. Ainsi en incrťmentant la valeur du TTL jusqu'ŗ obtenir un ťcho de retour, on trouve le chemin suivi par les datagrammes. Fonctionnement de IP.Identification des adresses locales.
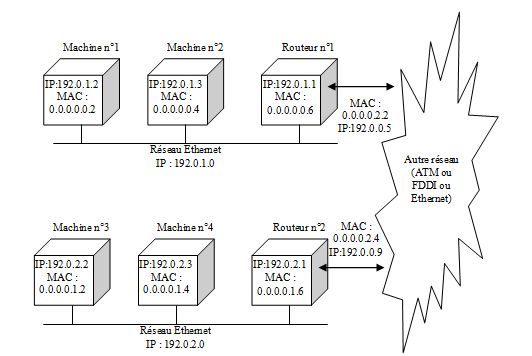
Lorsqu'une machine souhaite communiquer avec une autre, elle doit utiliser un support physique de Rťseau pour faire transiter ses donnťes. Prenons l'exemple d'un Rťseau fictif oý trŰne 3 machines. Ces 3 machines sont en fait un routeur et 2 ordinateurs. Chacun d'eux ŗ sa propre adresse IP et ŗ part le routeur qui utilise 2 types de Rťseaux, les 2 ordinateurs utilisent exclusivement le Rťseau Ethernet. On a donc la structure suivante:
On considťrera 2 cas, un premier oý la machine nį1 souhaitera parler ŗ la machine nį2, un autre oý la machine 2 souhaitera parler ŗ la machine 4. On ťtudiera aprŤs un exemple avec encore plus de Rťseaux. Dans notre premier cas, on va imaginer qu'un utilisateur sur la machine nį1 souhaite communiquer avec la machine nį2. Cette machine ayant ťtť inactive depuis trŤs longtemps, elle ne connaÓt pas ses voisins. Pour communiquer, elle a besoin de l'adresse physique de la machine cible (si celle-ci est sur le mÍme Rťseau qu'elle) ou alors de l'adresse physique du routeur si sa machine cible n'est pas sur son Rťseau local. Pour dťfinir l'adresse de son Rťseau, la machine source rťalise un ET logique entre son adresse IP et le masque. On trouve :
Le Rťseau est donc 192.0.1.0. La cible ayant pour adresse 192.0.1.3, on cherche, pour elle aussi, son Rťseau :
Les 2 machines sont donc sur le mÍme Rťseau. La machine source va donc demander ŗ toutes les machines du Rťseau celle qui a pour adresse IP : 192.0.1.3. Cette demande se fait en envoyant une requÍte ARP en BROADCAST ALL, c'est ŗ dire ŗ l'adresse de toutes les machines. On trouve donc une trame ARP contenant les informations suivantes :
Puis une trame de rťponse ARP viens de la cible qui rťpond :
Dťsormais les 2 machines se connaissent, elles communiquent entre elles par le truchement du Rťseau Ethernet, sans relancer de commandes ARP. Tant que ces 2 machines continueront ŗ discuter entre elles, elles conserveront localement l'association des adresses IP et MAC, dans la table ARP. De plus, une table de routage leurs permet de connaÓtre dťsormais la voie ŗ suivre pour se parler. Prenons maintenant le second cas : la machine nį2 souhaite dialoguer avec la machine nį4. On recommence alors la procťdure : Dťfinition du Rťseau de la machine source :
Dťfinition du Rťseau de la machine cible :
Les Rťseaux ťtant diffťrents, la machine source sait qu'elle ne peut pas discuter directement avec sa cible, elle doit donc impťrativement dialoguer avec son routeur pour obtenir le transfert des informations vers la cible. Comme la machine n'a pas dialoguť avec le routeur depuis longtemps, elle doit associer ŗ nouveau, ŗ l'adresse IP du routeur, l'adresse MAC de ce dernier. Pour cela elle lance une requÍte ARP en BROADCAST ALL.
Puis une trame de rťponse ARP vient du routeur :
Dťsormais, la machine nį2 sait parler ŗ son routeur. C'est maintenant ŗ lui d'ťtablir la fin de la communication. Pour cela, il existe plusieurs possibilitťs : le routage statique (le chemin ŗ suivre ŗ ťtť fixť par un administrateur) ou le routage dynamique (les routeurs doivent se dťcouvrir sans aide extťrieure). Mais quel que soit la mťthode de routage, le principe reste le mÍme, le routeur comme les autres machines, vťrifie la prťsence du Rťseau cible dans sa table de routage. Et si celui ci n'est pas prťsent, il consulte les autres machines gr‚ce ŗ des protocoles d'ťchange de routes (comme le protocole IRDP pour Internet Router Discovery Protocol).
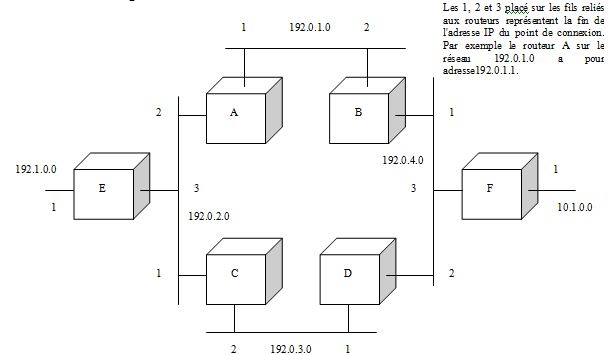
Le routage des paquets IP.Le protocole RIPLe principal protocole utilisť par les routeurs est le protocole RIP (pour Routing Information Protocol). Celui ci permet ŗ un routeur de dťfinir automatiquement et dynamiquement (c'est ŗ dire sans intervention extťrieure) le plus court chemin ŗ suivre pour atteindre une cible. Les informations de routages ne sont pas centralisťes mais sont diffusťes localement. Chaque routeur dispose de sa propre table de routage appelťe table RIP. Il n'y a pas sur le Rťseau, de núud centralisateur de l'information de routage, pas plus qu'il n'y a de routeur connaissant l'ensemble des Rťseaux disponible. La dťfinition du chemin le plus court passe par l'utilisation d'une mesure de distance, basť sur le HOP. Un HOP correspondant au passage d'un routeur. La distance n'est donc pas rťelle mais fictive, en effet, peu importe qu'un Rťseau mesure plusieurs centaines de kilomŤtres, ce qui compte c'est que l'on mobilise un nombre minimum de routeur pour transfťrer une information. La table RIP des routeurs stocke donc 3 informations : ∑ Le numťro IP du Rťseau destinataire (R). ∑ Le numťro IP du prochain routeur permettant d'y accťder (P). ∑ La distance en HOP totale du chemin (H). RťguliŤrement (environ toutes les 30 secondes), les routeurs diffusent leurs tables RIP. Heureusement, il existe 2 garde-fous ŗ ces ťchanges, qui sur un Rťseau aussi vaste qu'internet pourraient poser de gros problŤmes de saturation. Le premier tient au fait que les tables son propagťes avec une limitation ŗ 15 HOP de la distance maximale accessible. La seconde tiens au fait que seul le chemin le plus court est mťmorisť. Diffusion et constitution des tables RIPImaginons maintenant la situation suivante :
Dans ce Rťseau, toutes les boÓtes sont des routeurs. Ainsi par exemple, si on analyse le routeur A, on a la table RIP suivante :
Le routeur B lui, a la table suivante :
Ces tables sont entretenues dynamiquement, cela veut dire par exemple que si le Rťseau 192.0.3.0 est dťfaillant (par exemple, le lien est brisť), dŤs que le routeur C (ou le routeur D) essayera de transmettre sur ce Rťseau, il dťtectera une erreur et fera ťvoluer sa table de routage et par propagation celle des autres. Dans notre exemple prťcťdent, le routeur D aura les informations suivantes :
La crťation de ces tables de routage est rťalisťe par propagation de la table d'autres routeurs (en incrťmentant les distances), via des ťchanges de trames RIP. Par exemple, imaginons l'initialisation de la table RIP de A. On considťrera que A initie la propagation. ∑ A connaÓt naturellement les 2 Rťseaux auxquels il est reliť. Il envoie donc l'information que constitue sa table de routage en "BROADCAST" ŗ toutes les machines des 2 Rťseaux oý il est reliť (seul les routeurs retiendront cette information estampillťe RIP).
[NB] ∑ J'ignore volontairement le routeur de E puisqu'il n'apporte rien au cas ťtudiť. ∑ Le dťlai alťatoire sert dans le cas du Rťseau 192.0.2.0 ŗ ťviter une collision entre le retour de la table de C et celle de E. ∑ Pour A qui va recevoir, selon les valeurs alťatoires la trame de B ou de C en premier, va donc mettre sa table ŗ jour en incluant les 2 Rťseaux (192.0.3.0 venant de C et 192.0.4.0 venant de B). Les tables respectives de B et de C continues ŗ se propager. ∑ Le routeur D, comme A recevra en mÍme temps que A les informations provenant de B et de C, il va donc mettre lui aussi ŗ jour sa table et il va lui aussi la diffuser aprŤs un court dťlai. A ce point les 4 Rťseaux 192.0.X.0 sont tous connus, pour mieux comprendre le cheminement utilisť, on va synthťtiser ces rťsultats sous la forme d'un tableau.
Les distances devant Ítre minimisťes, aprŤs la troisiŤme ťtape, l'ensemble des ťlťments du Rťseau connaÓt le chemin le plus court pour atteindre sa cible. Si l'on ajoute les routeurs E et F, la diffusion est un peu plus longue mais elle conduira aux mÍmes rťsultats. La trame RIP
La trame RIP est encapsulťe dans une trame IP. Elle se compose d'un nombre variable de champs. Toutefois, au minimum, la trame RIP est composťe de 24 octets. La trame suivante est en octets.
Les champs ZERO sont des champs "vides" (remplis de zťro)
Une trame RIP peut contenir jusqu'ŗ 25 occurrences des champs ADDRESS et METRIC, permettant ainsi (pour chaque trame) de donner la position de 25 routeurs. Le champ METRIC permet de donner le nombre de HOP entre le routeur source et sa cible. Le nombre de HOP est limitť ŗ 15 (et il ne peut pas Ítre infťrieur ŗ 1), toutefois, il est possible de trouver dans le champ METRIC la valeur 16 qui signifie que le Rťseau est inaccessible. L'adresse IP de la passerelle ŗ contacter pour le routage est quand ŗ elle dans la trame IP qui encapsule la trame RIP. Les autres protocoles de routage.Relativisons bien les choses, RIP n'est pas un protocole de routage trŤs performant ŗ grande ťchelle. Pour des applications "locales", il est simple et facile ŗ utiliser, par contre ŗ grande ťchelle il n'est pas du tout adaptť (limitation ŗ 15 HOP du routage, trame trop longue pour peu d'informations). On utilise donc d'autres protocoles. Il existe une ťvolution du protocole RIP qui est RIP2, cette nouvelle version est plus puissante que RIP, mais somme toute assez peu diffťrente de son aÔeul. Nous n'ťtudierons donc pas ce protocole. Pour mieux comprendre dans quels cas on utilise le routage RIP, on a dťfinit 2 "zones" oý peuvent s'appliquer des rŤgles de rťflexion diffťrentes. On a donc une zone nommťe Intra-domaine et inter-domaine. L'intra-domaines, est une zone que vous "contrŰlez", c'est ŗ dire oý vous avez le contrŰle de l'ensemble des núuds. c'est vous qui fixez les rŤgles de routages, qui segmentez l'espace en sous domaines. Vous devez sťcuriser votre espace, mais pour ce faire, vous avez "tous les droits" puisque vous Ítes chez vous. L'inter-domaine est le pays des opťrateurs du monde des Rťseaux (cela coÔncide en gťnťral avec les grands opťrateurs tťlťphoniques). A moins de travailler pour ces grandes entreprises, vous n'avez absolument aucun droit d'influencer de quelque faÁon que ce soit sur leur domaine, ou de leur demander de s'adapter ŗ vos spťcificitťs. Pour les zones intra-domaine, RIP est encore le plus employť, mais le protocole OSPF (Open Shortest Path First) est en passe de le dťtrŰner. OSPF permet de contrŰler l'ťtat des liens, il est aussi plus rapide ŗ se stabiliser que RIP. On trouve aussi les protocoles IGRP (Interior Gateway Routing Protocol) et E-IGRP (Enhanced IGRP). Pour les zones Inter-domaine, on trouve des protocoles tels que BGP (Border Gateway Protocol), IS-IS (Intermediate System to Intermetiate System), OSPF, etcÖ L'utilisation de la version 6 de IP fournira sans doute une normalisation des fonctions de routage, avec peut Ítre l'apparition de nouveaux protocoles.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||